What’s The Project About?
Predicting Group Stage of the 2022 FIFA World Cup
GitHub Link: github.com/vedangwartikar/fifa-2022-group-stage-pred
Project Overview
This project aims to compare various machine learning models to predict the outcomes of FIFA World Cup 2022 matches. The objective is to determine which model performs best in predicting match outcomes and tournament progression. Furthermore, a custom implementation of top-performing models was developed to simulate match results based on historical data.
Motivation
With the FIFA World Cup 2022 being an ongoing global event at the time of this project, it presented a unique opportunity to apply machine learning models to real-world sports data. The goal was to explore how machine learning can benefit sports analysis, aiding strategic decision-making in match predictions, substitutions, and game tactics.
Data Sources
Three datasets were used in this project:
international_matches.csv: Used for building and training the models, consisting of around 6,000 processed matches.fifa_rankings_2022.csv: Contains FIFA rankings for teams as of 2022, used to make predictions for World Cup matches.world_cup_teams.csv: Contains the official tournament schedule, teams, and stages to sequentially predict match outcomes.
Key Features
- Team FIFA Rank: The current rank of the home and away teams.
- Team FIFA Points: The total FIFA points for each team.
- Match Outcome: Binary classification, indicating if a team wins (1) or loses/draws (0).
The project focuses on predicting whether a team qualifies for the next round based on these features.
Machine Learning Models Used
We evaluated multiple machine learning models to determine their performance on the dataset:
- Logistic Regression
- Naive Bayes
- Decision Tree
- K-Nearest Neighbors (KNN)
- Support Vector Machines (SVM)
- AdaBoost
Train and Test Accuracies
The comparison between train and test accuracies across models is shown below:
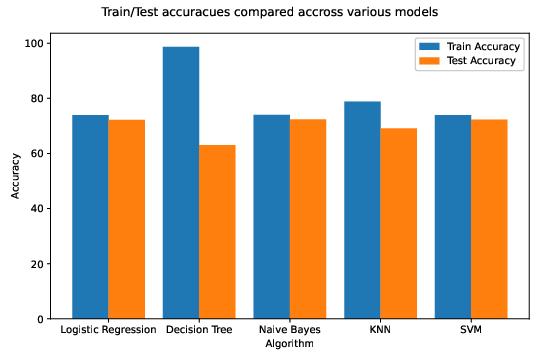
From the above figure, Logistic Regression, Naive Bayes, and SVM performed well, with Decision Tree overfitting the training data.
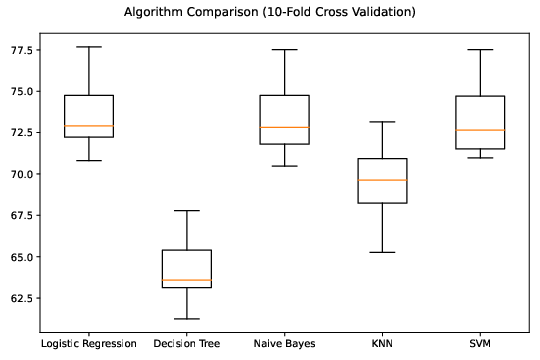
Cross-Validation Results
We applied 10-fold cross-validation to assess the model performance. The results show that Logistic Regression and Naive Bayes achieved the highest median accuracy, approximately 73%.
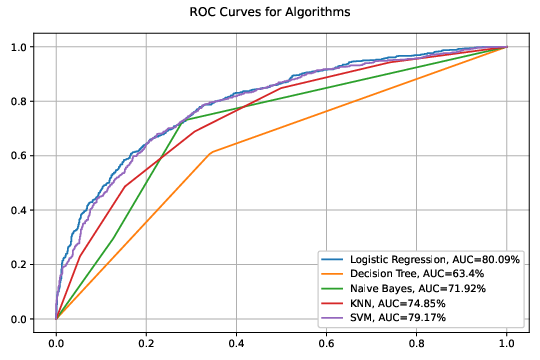
ROC/AUC Curves
The ROC curves highlight that Logistic Regression performed the best in terms of AUC, with SVM and Naive Bayes following closely behind.
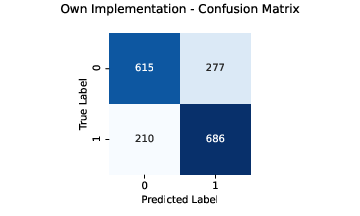
Custom Model Implementations
In addition to using pre-built models from the scikit-learn library, we implemented Logistic Regression and Naive Bayes from scratch.
Logistic Regression Implementation
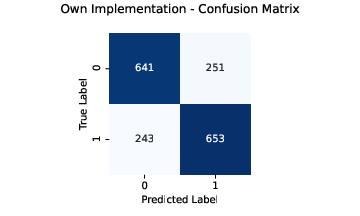
The model was built using the gradient descent algorithm, and performed slightly better than the scikit-learn implementation. Below is the confusion matrix for both:
- Custom Logistic Regression Accuracy: 72.76%
- scikit-learn Logistic Regression Accuracy: 72.15%
Naive Bayes Implementation
The custom Naive Bayes model also achieved similar performance to scikit-learn’s version, with an accuracy of 72.37%.
Decision Tree
Although Decision Tree was implemented, scikit-learn’s version performed significantly better. The custom Decision Tree struggled with generalization, particularly on deeper trees.
World Cup Simulation Results
We used the best-performing algorithm (Logistic Regression) to simulate the World Cup schedule and predict outcomes match-by-match.
For instance, the model correctly predicted the outcome of Costa Rica vs. Spain, where Spain was predicted to win with a 67.49% probability. However, some predictions were incorrect, as underdog teams such as Morocco performed better than expected.
Prediction Accuracy by Stage
- Group Stage Accuracy: 68.75%
- Round of 16 Accuracy: 75%
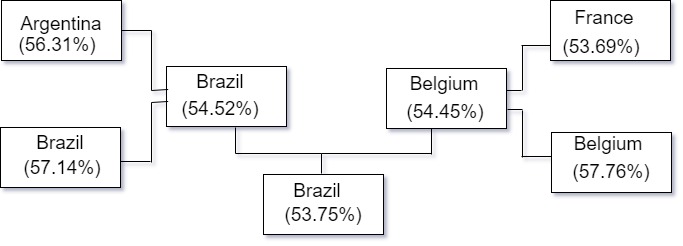
Here’s the final group stage prediction (visualized)
Feel free to contribute through a PR or report any issues here.